喜訊:啄醫生醫療大模型在最新的中文醫療模型評估中(CMB-Exam)排名第一!
熱點
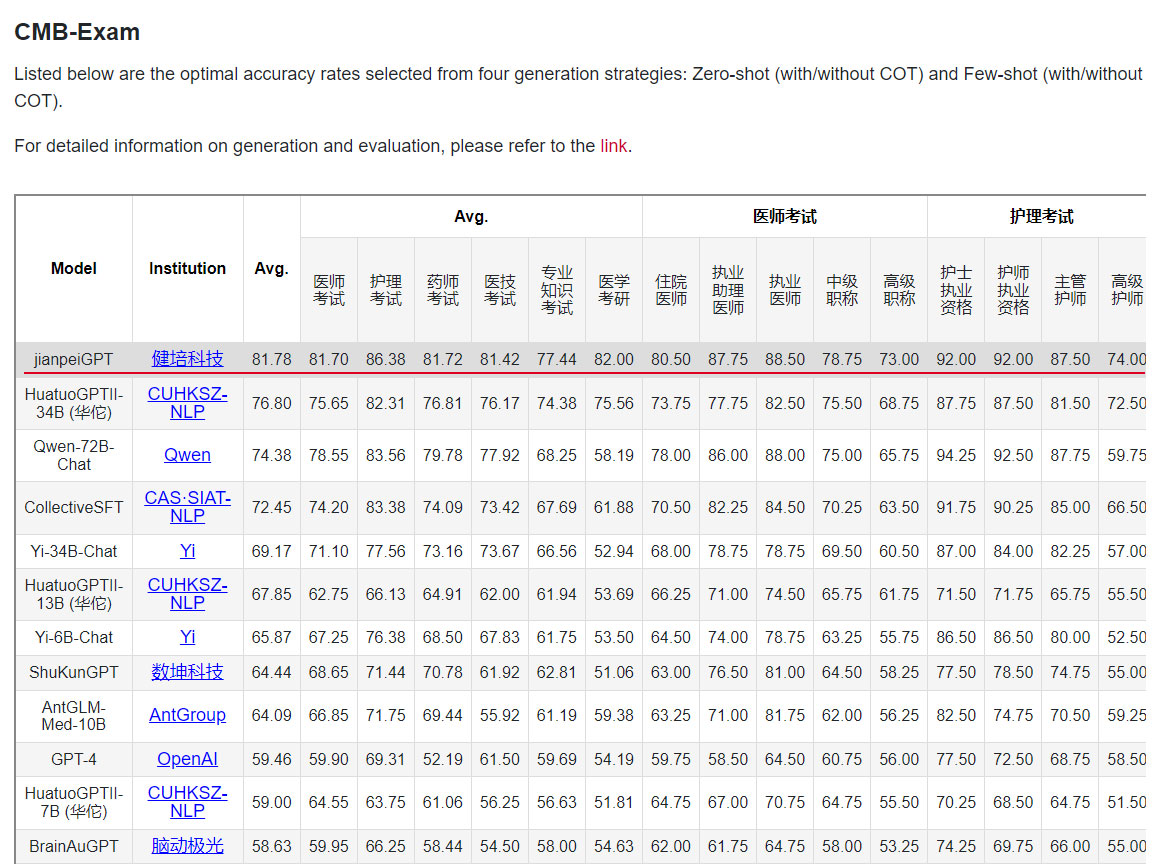
近日,CMB官方發布了最新的中文醫療模型評估(CMB-Exam)排名,列出了從四種生成類別中選擇的最佳準確率:Zero-shot (with/without COT) and Few-shot (with/without COT) 生成和評估的詳細信息。包括香港中文大學、阿里云通義千問、中科院深圳先研院、螞蟻集團、美國人工智能研究公司等團隊成功上榜。其中健培科技啄醫生醫療大模型??jianpeiGPT 以 81.78 平均分位列第一。
啄醫生團隊基于龐大的醫療行業數據集、自主開發的多學科專業知識庫、以及豐富的臨床實踐,訓練的醫療垂直行業大模型,已經在多個場合落地應用。在CT、DR、MRI、眼底等影像上實現了AI輔助疾病診斷,并在醫療數據質控、健康篩查、隨訪、手術規劃等全流程環節應用,幫助提高疾病診療的質量和效率。
啄醫生大模型??JianpeiGPT
啄醫生團隊在醫療健康大模型的研發上具備深厚積累,在數據、算法和落地能力方面優勢明顯。
數據層面,圍繞醫療垂直領域中防、篩、診、治、康各環節,提煉海量高質量的醫學知識數據形成上百億token的高質量醫學知識專庫,以及上萬份醫學指南、幾千萬例次真實病歷等。海量高質量的訓練數據,保證了“啄醫生”醫療大模型響應的可靠性和準確性。
算法層面,通過高效的分布式計算技術、硬件加速器技術支持,高效持續訓練“啄醫生”醫療大模型,激發大模型對醫療場景的強大的理解、生成、邏輯和記憶能力,為“啄醫生”醫療大模型開發和高效快速迭代提供強力支撐。
關于CMB
CMB是一個全方位、多層次的中文醫學基準。它包含了280,839道題和74道復雜病例會診題,涵蓋了所有臨床醫學專業和各種專業水平。該平臺旨在全面評估大模型的醫學知識和臨床咨詢能力。具體組成如下。
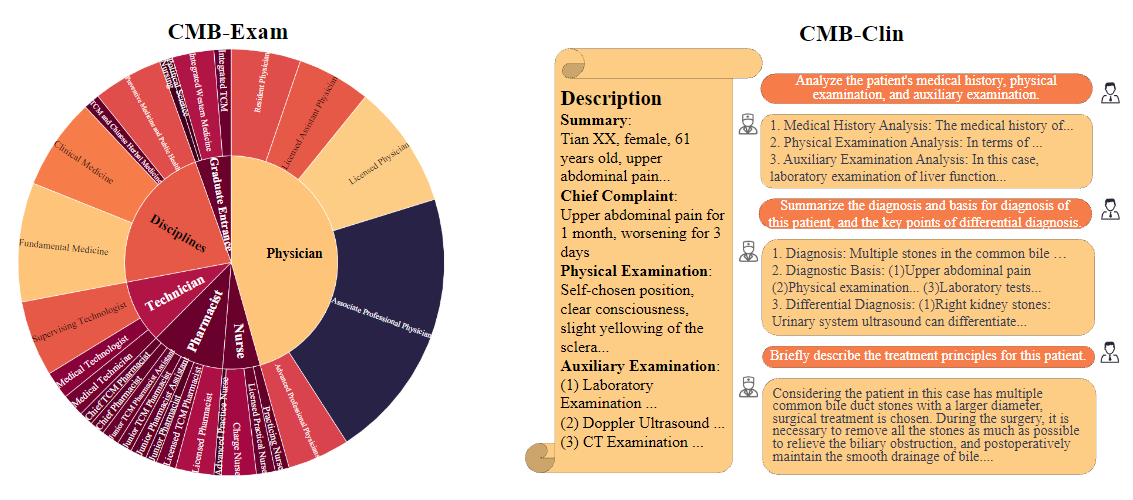
中文醫療模型評估基準 CMB,其包括了醫學知識的多層次綜合評估(CMB-Exam)和基于真實病例的復雜臨床診斷問題(CMB-Clin)。其中 CMB-Exam 的構建理念是反映真實醫療領域的考核體系,覆蓋了醫生、藥劑師、醫技科室、護士崗位,對于一致的大學學科知識考試和研究生入學考試進行了合并,歸納出了六個類別。以此來評測出模型對于醫療知識的掌握程度。CMB 從現實醫學考核和臨床應用出發,結合選擇題和復雜病歷問診來全面檢驗模型在醫學知識與診斷能力上的表現。為醫學大模型的研發者們提供有力的反饋,幫助更快地完善模型,促進中文醫學領域語言模型的持續創新和應用。?
